
It’s 2 AM.
You are chasing a lateral-movement alert that finally starts to make sense.
The account activity lines up. The host sequence lines up. The timeline is ugly, but it is beginning to tell a story.
So you go to pull the authentication logs that started it.
They are gone.
Aged out at 90 days.
The part of the incident you needed most disappeared a month before you got the chance to read it.
That is the moment the real problem becomes obvious.
The detection did not fail. The retention did.
And even retention is not the root issue. It is just the place where the architecture finally exposes itself.
Most security teams have quietly accepted a bad trade: collect less, keep less, and see less, so the SIEM bill does not keep growing.
We call it optimization. We call it noise reduction. We call it cost control.
But in practice, we have normalized blinding ourselves to stay within budget.
That is not a discount. It is not efficiency. It is a visibility tax built into the way most SIEMs are designed.
When ingestion, storage, and detection are tightly welded together, every new log source becomes a financial decision. Every additional GB has to justify itself. Every noisy source becomes a candidate for filtering, sampling, dropping, or shorter retention.
Over time, the question changes.
It stops being: “What do we need to see?”
It becomes: “What can we afford to keep?”
That is where SIEM architecture starts shaping security outcomes.
Because a blind spot is rarely just missing data. It is a missing correlation. One authentication event gone. One endpoint signal unparsed. One cloud log dropped because it was too expensive. And suddenly the attack path never connects.
The events existed. The story existed. The system just was not allowed to keep enough of it.
This piece is about that architecture.
Specifically, what changes when a SIEM stops being only a place where logs are collected, and starts becoming a system that collects, parses, normalizes, filters, enriches, routes, stores cheaply, and correlates events while they are still moving.
All on one foundation the security team actually owns.
Because the future of SIEM is not just better detection logic.
It is better control over the data pipeline that makes detection possible.
Key takeaways - Per-GB pricing turns logs into liabilities. When ingestion, storage, and analytics are welded together, every new source taxes all three, so teams drop data to control spend. - A blind spot is a missing correlation. When the right logs are absent or unparsed, the events that would connect into an attack never link up. SIEMs turn only about 22% of the ATT&CK techniques their data could cover into working detections (CardinalOps, 2025). - Collecting was never the hard part. Standardizing is. Normalizing every event to one open schema is what makes detections, dashboards, and hunts work across every source. - A lakehouse-native architecture decouples cost from value. Keep everything, store it cheaply and searchably for years, and correlate it as it arrives, without a per-GB toll booth. - Owning the stack ends the lock-in. One open schema and your own unified data lake give you the freedom to deploy on-premises, in your cloud, or as SaaS—the choice is yours, not the vendor's.
Most SIEM bills are tied to one number: how many gigabytes you send in. That single pricing decision quietly reshapes your entire security program. Every firewall you add, every cloud account that grows, every chatty endpoint becomes a line item, so teams do the rational thing and send less.
And there’s a lot to send. The average enterprise SIEM now ingests 23,746 unique log sources across 259 source types, with unique sources up 18% year over year and source types up 30% (CardinalOps, 2025 State of SIEM Detection Risk). Gartner found organizations run an average of 45 cybersecurity tools (Gartner, 2025). In Vectra AI’s survey of 2,000 practitioners, 73% run more than 10 tools and 45% run more than 20 (Vectra AI, 2024 State of Threat Detection).
Now point all of that at a meter that charges by the gigabyte. You get the trade every SOC knows by heart: ingest it, or investigate it. Pick one.
So logs get sampled. Sources get left off. “We’ll add that one next quarter” becomes a permanent state. The budget stays flat and the coverage quietly shrinks, and nobody decides this on purpose. The architecture decides it for you.
The money is the part you can see. The damage is the part you can’t. Real detection is almost never one event tripping one rule. It’s correlation: tying separate events together until they add up to an attack.
Picture a real one. At 2:14am a login succeeds from a new country. At 2:16am multi-factor authentication is switched off for that same account. By 2:40am a fresh mailbox rule is quietly forwarding every invoice to an outside address. On its own, each event is a shrug: a trip, an admin tidying settings, a user filtering their mail. Strung together, in that order, inside half an hour, it’s an account takeover in progress.
That chain only gets caught if every link is present and readable. Drop the sign-in log to shave your ingest bill, or let the mailbox event land as unparsed text no rule can match, and the line between the dots never gets drawn. The attack was sitting in your data the whole time. The correlation that would have named it never happened.
This is why “we have a SIEM” and “we can detect that” are not the same sentence. Enterprise SIEMs collect enough data to cover roughly 90% of MITRE ATT&CK techniques, but turn only about 22% of it into working detections (CardinalOps, 2025). The raw material is there. The connections are not.
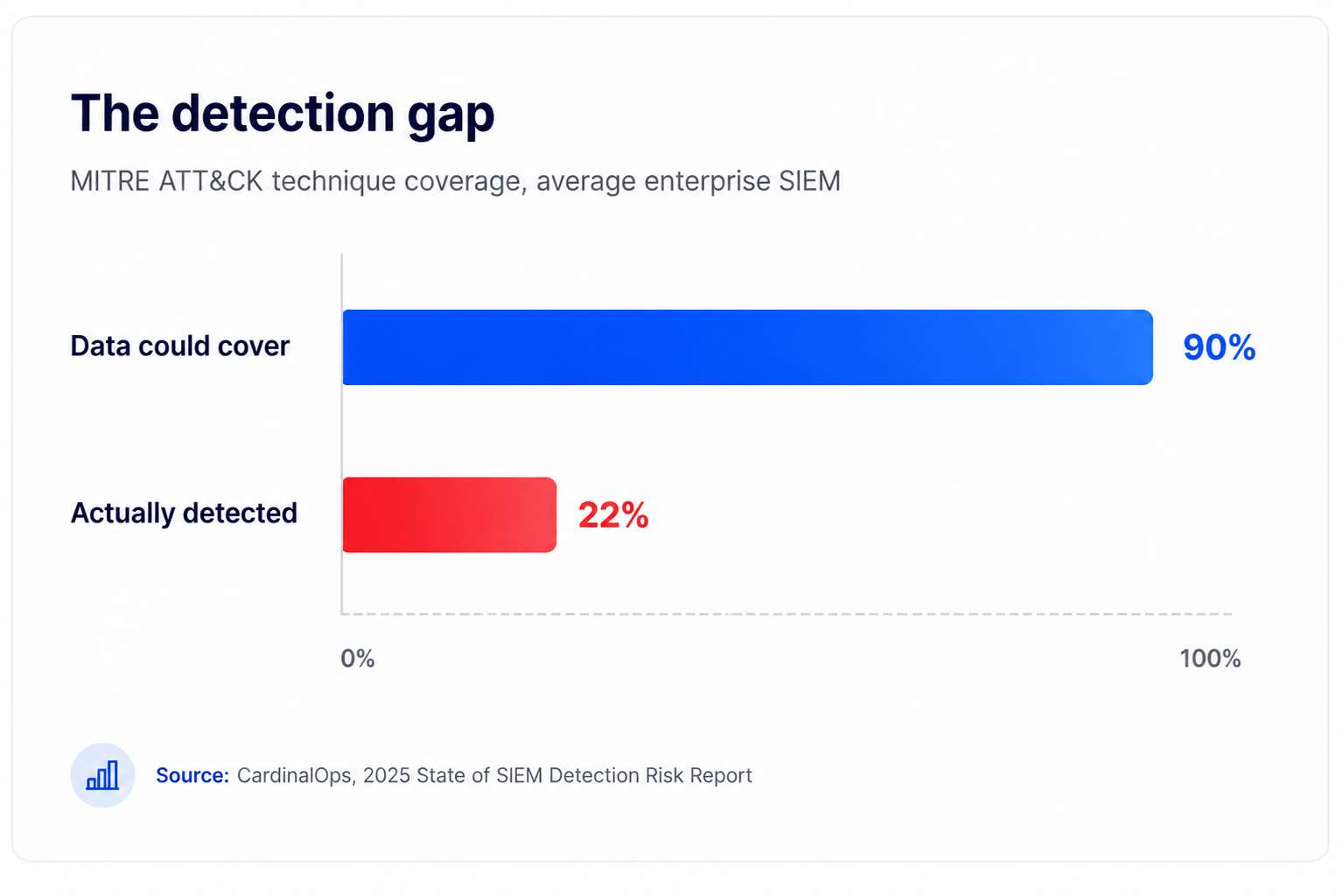
The detection gap. The average enterprise SIEM has data that could cover about 90% of MITRE ATT&CK techniques but operationalizes detections for only about 22%. Source: CardinalOps, 2025.
And that assumes your SIEM can correlate at all. In many of them it can’t, at least not on its own: tying that sign-in to a firewall block to a cloud API call is a manual hunt, an analyst pivoting between consoles trying to remember which events belong to the same actor before the trail goes cold. That is not how it should work. A dedicated correlation engine joins those events for you, on the live stream, the moment they arrive, so the chain assembles itself instead of waiting for someone to piece it together by hand.
None of this is a tuning problem. It traces back to the same structural choice as the cost trap: when keeping and normalizing data is expensive, you keep less and normalize less, and the correlation quietly starves for the one event it needed. The fix isn’t a cleverer rule. It’s an architecture where the right data shows up, in the right shape, and gets correlated the moment it lands.
A SIEM that only collects logs is a very expensive tape recorder. Raw logs are a mess of formats, a “failed login” looks completely different coming from Azure AD, AWS IAM, and on-prem Active Directory, and until you fix that, every detection rule and every dashboard is brittle. The hard part, the valuable part, is standardization.
So the work that matters happens in the pipeline, before data ever lands. Picture one log’s journey through it.
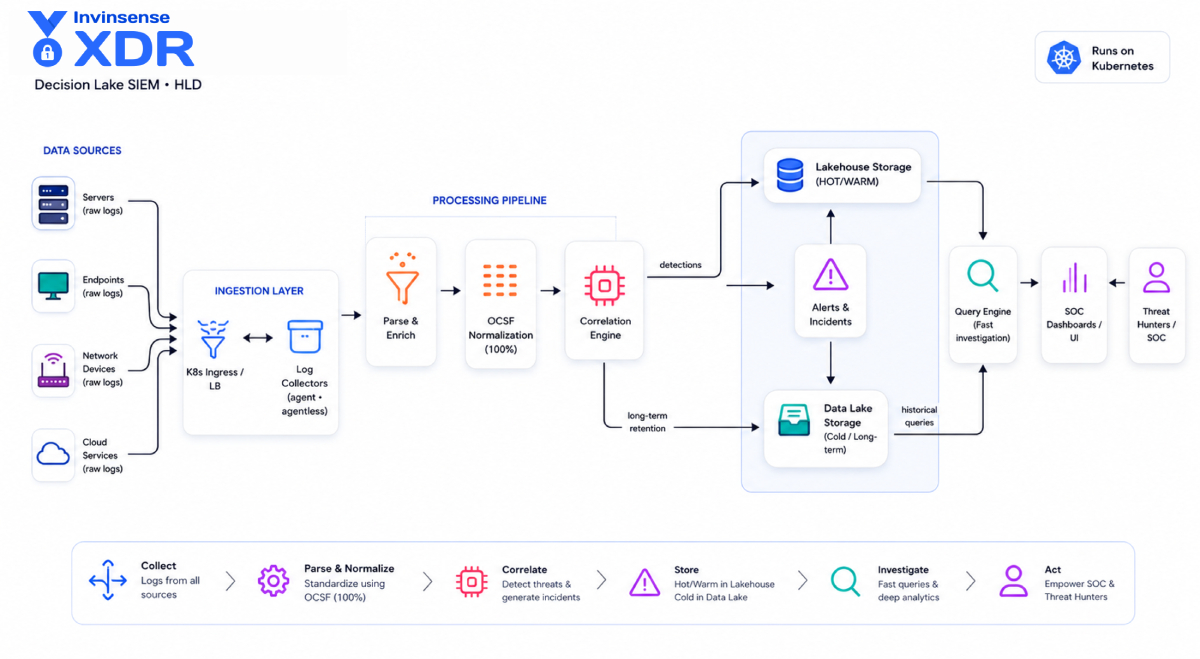
Invinsense Security Data Lake high-level architecture: raw logs from servers, endpoints, network devices, and cloud services pass through the Log Collectors, parse and enrich, and 100% OCSF normalization into the Correlation Engine, which feeds Lakehouse hot and warm storage, alerts and incidents, and cold data-lake storage, all queried through the SOC UI.
Invinsense Security Data Lake, high-level architecture. Brand components: Log Collector, Correlation Engine, Lakehouse, Data Lake Storage, Query Engine.
It arrives raw, in whatever the source emits, syslog or JSON or CEF or something proprietary. The Log Collector parses it into structured fields, then maps it to the Open Cybersecurity Schema Framework (OCSF) 1.8.0, an open standard with 83 event classes across 9 categories. Every event, from every source, comes out speaking the same vocabulary. Then it gets enriched with context like geo-IP, asset ownership, and threat-intel scores, filtered so noise doesn’t ride along, and routed onward.
That OCSF step is the quiet hero. Write one rule against severity_id >= 4 and it works across CloudTrail, Microsoft 365, and your EDR without a single source-specific tweak. A “user” is a user everywhere. Dashboards stop breaking when a vendor changes a field name. This is the opposite of the schema drift that breaks rules every quarter.
And when a brand-new source shows up that no security tool recognizes? An AI Autoparser reads sample logs, picks the right OCSF class, writes the transform, and validates it through a six-gate pipeline that self-corrects until it passes, with no human writing parser code. That’s the maintenance treadmill, the one behind those 16 dead rules, taken off your engineers’ plates.
Here is the architectural move that breaks the per-GB curse: a decoupled SIEM. The traditional SIEM welds ingestion, storage, and analytics into one billable unit, so scaling any one of them taxes all three, and your logs stay locked in the vendor’s proprietary store. A decoupled architecture pulls two things apart. First, storage from compute, so keeping data no longer means paying for analytics horsepower you aren’t using. Second, your data from the vendor: every event is normalized to an open schema and kept in a lake you own, so it stays yours to search and move, whatever you run on top of it.
In practice, that looks like a security data lake with tiers. The hot Lakehouse answers queries across billions of rows in under a second, while older data flows automatically into searchable long-term storage on S3-compatible object stores, Azure Blob, or Google Cloud Storage. It stays queryable. That 2am hunt across last quarter’s logs runs against the archive instead of dead-ending at a 90-day wall.
Because each layer scales on its own, cost stops tracking data volume. There’s no per-GB ingestion penalty, columnar compression reaches up to 23x, and you keep 100% of your raw logs for years instead of summarizing them away. The industry data backs the principle: decoupling ingestion from analysis routinely cuts what hits the expensive tier by 50% or more (Cribl, 2024-2025). You’re no longer paying a premium to keep your own evidence.

Storing everything cheaply solves the forensics problem. It doesn’t, on its own, catch the attack while it’s happening. For that, detection has to run on events as they move, not on a scheduled query that wakes up every few minutes after the data has already landed.
That’s what a streaming Correlation Engine does. It reads the full stream of normalized OCSF events and correlates them in real time, across sources, on a shared key. Real attacks don’t happen in one log line. A failed-login burst, then a successful login from a new country, then MFA disabled, then an inbox forwarding rule. Each event alone is shrug-worthy. Tie them to the same user across endpoint, identity, cloud, and network, and it’s an attack in progress. When a detection matches, it writes straight back into the Lakehouse, searchable the instant it fires.
This is how you push against that 241-day dwell time. You stop waiting for the batch.
You can buy your way to most of this. Bolt a data-collection pipeline onto a cheap object store, wire that into a separate SIEM, glue on a correlation layer, and keep all four integrations alive. Plenty of teams do. It’s also a second full-time job, and it’s where a real chunk of that 45-tool sprawl and broken-rule count comes from.
The alternative is having it converge by design. Collection, OCSF normalization, enrichment, routing, the data lake, searchable archives, and streaming correlation as one platform, configured in a UI instead of hand-written YAML, with hot-reload on every change so nothing restarts, and per-source isolation so one noisy feed can’t starve the rest. Onboarding a source becomes a form, not a three-week project.
And it settles the SaaS question. About 35% of organizations stayed on an incumbent SIEM even after evaluating alternatives (IDC, 2024), often because the data and the schema were trapped. An open schema and a lake you own flip that. Deploy on-prem, in your own cloud account, or fully managed as SaaS. That’s a deployment choice you make for operational reasons, not a hostage situation. Your data stays yours, in a format anyone can read.
The point isn’t that collecting logs is easy and everyone does it. It’s that collecting was always the least important thing your SIEM does. The value is in what happens to the data between the source and the screen: standardized, kept, searchable, and correlated. Get the SIEM architecture right and the cost problem you thought you had mostly disappears, because it was never really a cost problem.

Discover complete cybersecurity expertise you can trust and prove you made the right choice!


